数字图像分类digital image classification
借助电子计算机系统或数字图像处理系统, 根据光谱信息、空间信息或时间信息特征,将数字图像划分为互不相同的部分,以便于识别的处理过程。
数字图像分类主要应用于自然资源调查、医疗诊断等领域。如分类处理陆地卫星(Landsat)的数字图像可把处理范围内的地球表面划分为河流、耕地、林地等地类,确定这些地类的位置,计算它们的面积;分类处理不同时间内获得的数字图像可划分不同农作物的种植范围、区分出不同农作物的生长发育状况和受害程度,等等。根据处理数字图像的方式,形成统计模式识别和句法模式识别两大数字图像分类方法。前者以图像的光谱信息为主要的分析对象,以数学上的决策理论为基础,从大量的统计分析中找出规律性认识,提取反映图像本质特点的特征以供识别;后者起始于20世纪60年代后期,它以图像的结构信息为主要的分析对象,研究点、直线、斜线、弧线及环等构成图像的规则,用来识别图像,但尚未应用于生产实践。根据处理光谱信息的方式,统计模式识别可分为以下几种方法:
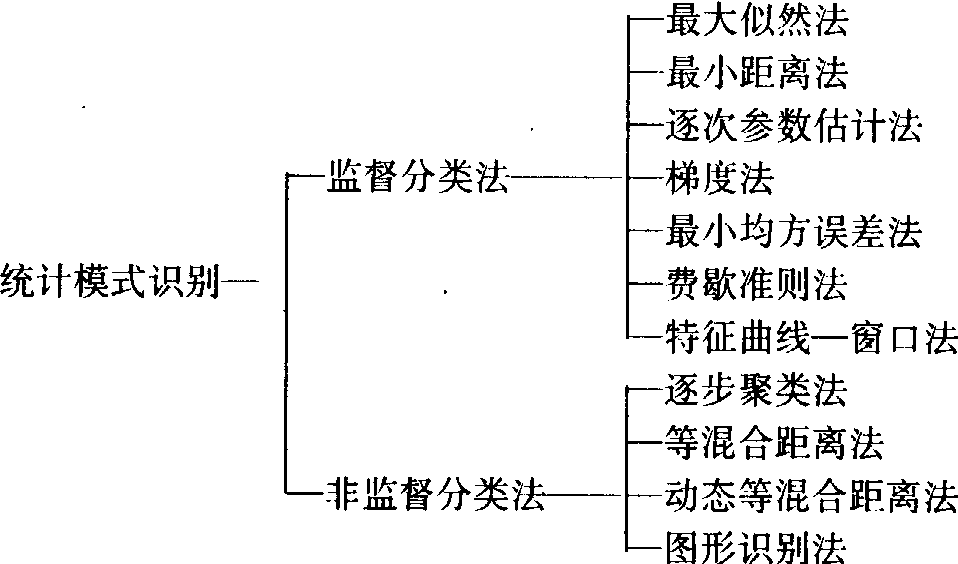
监督分类法 根据人事先指定的已知训练场地提供的样本,通过选择光谱特征参数、建立判别函数来对未知类别的像元进行分类处理。计算机对训练场地内的已知像元的光谱特征进行分析统计,提炼出这些类别的光谱特征参数或建立相应的判别函数,作为区分其余未知类别的像元的依据。利用训练场地的已知像元训练计算机或估计参数,从而形成判别函数的过程,是监督分类的学习过程;利用判别函数对未知类别的像元进行识别分类的过程,称为监督分类的识别分类过程。这两个过程的关系见图1。由于提供的训练场地所包含的已知像元总是少量的,未知像元总是大量的,故要求已知像元具有代表性,以保证分类结果具有足够的精度。
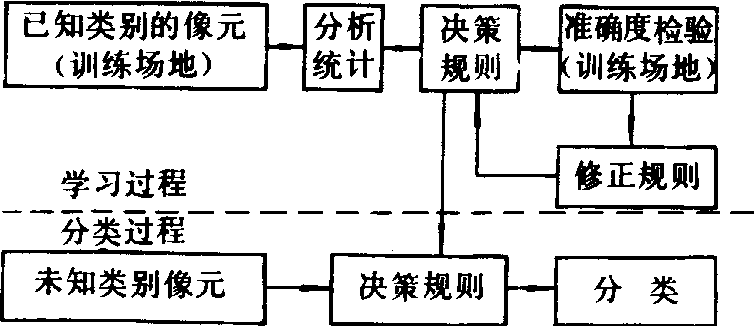
图1 监督分类法流程图
最大似然法是常用的监督分类法。用这种方法对数字图像进行分类处理时,首先由人确定待分的类别数C,指出各类别的训练场地的位置及出现的概率Pi(i=1,2,……C),然后由计算机根据训练场地内已知像元的光谱值
Xj=(x1,x2……xn)T (1)
按下式统计出各训练场地内所有已知像元的光谱均值方阵Mi及均方差阵∑i

式(1)~(3)中,mi为第i个训练场地内已知像元的个数;Xij是第i个训练场地内已知像元j的光谱信息,共有n个分量,即x1、x2……xn;n是分类处理所用的谱段数;Mi及∑i表明在n个谱段的光谱信息构成的n维特征空间中,类别i的光谱分布区域的重心位置、大小和形状,反映出该类别的已知像元的光谱统计特征。图2给出小麦、水体、盐碱地在由陆地卫星5、7两个谱段构成的二维空间中的光谱特征椭圆体。椭圆体越小,该类像元的光谱取值范围越集中,反之越离散。根据公式
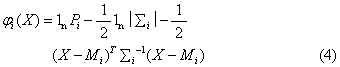
非监督分类法 根据像元间的类似度大小进行合并归类,从而识别未知像元。同类像元具有相同的光谱特征而凝聚在同一光谱特征空间内,不同类别的像元则因其光谱特征不同而凝聚在不同的光谱特征空间区域内,从而形成不同的群体(见图2)。在光谱特征空间内,类与类之间的距离(即类似度)可用不同的方式定义,从而形成不同的非监督分类法。
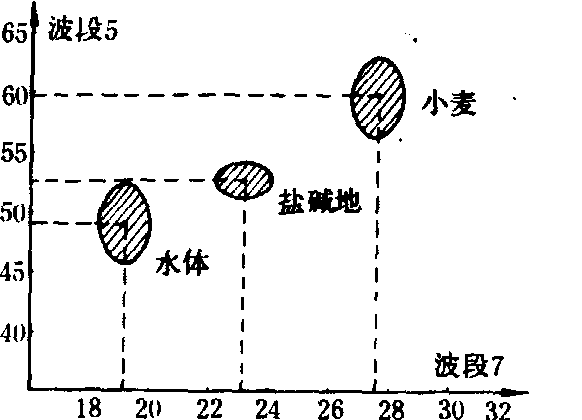
图2 小麦、水体及盐碱地的光谱特征
逐步聚类法是常用的非监督分类法。它根据各像元的光谱信息的内在相似性,用不同方法(如欧氏距离)作为衡量类似度的指标,在逐步迭代过程中把所有的像元划分为不同的类别。其分类步骤如下:❶选定k个类别的原始聚类中心M1,M2……Mk,作为各像元的凝聚中心;决定标准差S、相似距离D、每一类别的最少像元数MIN、分组中心数C,作为控制聚类迭代过程的阈值。在迭代过程中,凝聚中心会比k大,也可能比k小。
❷计算各像元相对于k个聚类中心的相似度,通常是计算各像元的光谱值到Mi的欧几里得距离Dv把像元划入Di取值最小的那一类内。
❸计算各类别的新的聚类中心Mi的值,它们反映出经第二步处理后各类像元的光谱特征。
❹根据阈值调整各类的中心值,若两类的中心之间的距离小于D,则合并为一类;若某类包含的像元数小于MIN,则将其合并到与其最相似的另一类内;若某类内像元光谱值的均方差大于S,则将其分裂成两类。调整后重新计算新的聚类中心Mi的值。
❺决定终止聚类或转移到第二步继续迭代作业。若现有的类别数k等于或大于C,或任一聚类中心的新旧值之差小于S,均可终止聚类作业,此时所有像元都被划分到不知其名的不同类别内,它们的真实类别要根据经验或实地对照才能确定。
逐步聚类的原始聚类中心是任意指定的,在迭代过程中又利用阈值来调整分类结果,各像元的归属和类别数都会发生变化,所以是一种不需要训练的动态分类法。
由于理论上和技术上的不完善以及遥感技术本身发展的阶段性限制,数字图像分类技术处理遥感图像的能力跟遥感系统收集信息的能力相差较大,表明数字图像分类技术急待发展。它的发展方向是:把遥感信息和非遥感信息结合起来,把不同谱段、不同空间的遥感信息结合起来,提高分类处理的精度;在完善统计模式识别技术的同时,引入句法模式识别技术,提高分类处理的质量,研制更好的图像处理硬件系统,提高图像处理的速度;应用最新的科研成果,提出准确合理的数学模型,建立更优化的分类处理算法。
- 9.人口迁移是什么意思
- 9. 什么是社会主义的人口规律是什么意思
- 9. 什么是等价交换是什么意思
- 9. 什么是财政赤字是什么意思
- 9. 价值规律的内容是什么意思
- 9.优良牧草和牧草种子是什么意思
- 9.会计、会计学是什么意思
- 9. 会计原则的有关问题是什么意思
- 9.信托与抵押是什么意思
- 9.兔及兔产品是什么意思
- 9. 关于1:8的经验数据是什么意思
- 9. 兴化市是什么意思
- 9.其它是什么意思
- 9.其它作坊是什么意思
- 9.其它农用机械是什么意思
- 9.养狗和养猫是什么意思
- 9.军功、嘉奖等是什么意思
- 9.军用卫星是什么意思
- 9.农产品加工机械是什么意思
- 9. 凤凰山风景名胜区是什么意思
- 9.包装是什么意思
- 9.半导体是什么意思
- 9.南昌县蒋巷联圩是什么意思
- 9.原子能技术是什么意思
- 9.原油产品是什么意思
- 9.变奏曲式是什么意思
- (9)台湾是什么意思
- 9号三体综合征是什么意思
- 9号染色体病理基因组是什么意思
- 9号环状染色体综合征是什么意思
- 9.合江县是什么意思
- 9.吉林农业杂志社是什么意思
- 9.吉林省农业机械化科学研究所是什么意思
- 9.吉林省吉保电子实业公司是什么意思
- 9.吉美农业技术有限公司是什么意思
- (9)同形词词典是什么意思
- (9) 同族是什么意思
- 9.吕泗渔港是什么意思
- 9.和声配置法是什么意思
- 9.唱名法是什么意思
- 9. 商水县是什么意思
- 9.商洛地区农业科学研究所是什么意思
- 9. 喀喇沁左翼蒙古族自治县是什么意思
- 9.困难与问题是什么意思
- 9.国家扶植政策是什么意思
- 9.地图是什么意思
- 9. 城市化的涵义是什么意思
- 9. 基本建设产品和建筑产品是否同时存在是什么意思
- 9. 夏河县是什么意思
- 9.外交文书是什么意思
- 9. 大方县是什么意思
- 9.太湖地区农业科学研究所是什么意思
- 9 女性文化是什么意思
- 9. 如何评价两个平行的世界市场的理论是什么意思
- 9. 如何评价物资流通的社会经济效益是什么意思
- 9.学生班、组是什么意思
- 9. 安岳县是什么意思
- 9.宗教节日是什么意思
- 9. 定兴县是什么意思
- 9.定西地区农业技术推广站是什么意思