总体均数估计
总体均数估计
总体均数的估计有点估计和区间估计。点估计是用样本均数来估计总体均数; 区间估计是求出总体均数的可能范围,方法随总体标准差是否已知而异: 总体标准差未知时按t分布原理计算; 总体标准差已知时按正态分布原理计算。此外,亦可用平方根纸图解求总体均数的可信区间。
总体均数的可信区间
(1)总体标准差未知时,一般按式(1)或式(2)计算可信区间。当样本含量n较大时,比如n>50,亦可按式(3)作近似计算,n越大,近似程度越好。因为根据统计量t的抽样分布原理:
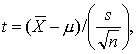
式中μ为总体均数,为样本均数, s为样本标准差,n为样本含量。t的抽样分布曲线表明: 在界值-tα,v和tα,v以外的面积为α,如t≤-t0.05,v和t≥t0.05,v的概率为 α=0.05; 而在此两界值以内的面积为1-α,如-t0.05,v
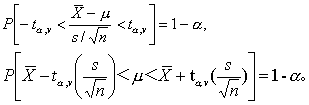 于是得可信度为1-α 时计算总体均数的可信区间的通式为
于是得可信度为1-α 时计算总体均数的可信区间的通式为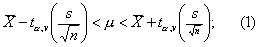
或写成
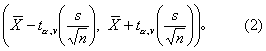
当v为无限大时,t分布呈正态分布,实用上当样本含量足够大时,式(2)可近似地用式(3)来代替,即
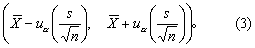
(2)总体标准差已知时,按式(4)计算可信区间。由于实际工作中,总体标准差常为未知,故本法少用。
若从正态总体作随机抽样,当总体标准差σ已知时,统
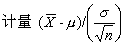 为标准正态分布,故总体均数的1-α可信区间为
为标准正态分布,故总体均数的1-α可信区间为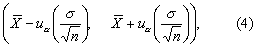
例1 某矿对11名无矽肺矿工测血清铜蓝蛋白含量(活性单位/dl),算得均数为6.5,标准差为1.36,试估计无矽肺矿工血清铜蓝蛋白的总体均数。
本例n=11, =6.5, s=1.36,自由度v=11-1=10。若取95%可信区间,则α=0.05,查t界值表t0.05,10=2.228,按式(2):
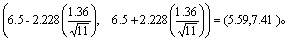
故无矽肺矿工血清铜蓝蛋白的点估计为6.5活性单位/dl,其95%可信区间为5.59~7.41活性单位/dl。
例2 某地500名健康成人末梢血液白细胞均数为7291个/mm3,标准差为1695个/mm3,试估计该地健康成人白细胞均数。
本例n=500, =7291,s=1695,若取95%可信区间, u0.05=1.96,按式(3):
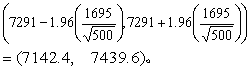
故该地健康成人末梢血液白细胞均数的点估计为7291个/mm3,其95%可信区间为7142~7440个/mm3。
两总体均数差值的可信区间 经假设检验,已知两样本均数X1与2有差别,而两样本方差s21与s22的差别无显著性时,须进一步估计两总体均数差值的大小。则以两样本均数之差|1-2|作为点估计。 用式(5)作区间估计。
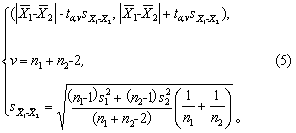
式中n1、n2分别为两样本含量,s1、s2分别为两样本标准差,s1-2为两样本均数之差的标准误。
例3 分别用甲、乙两药治疗某病患者,甲药治40人,乙药治38人。测得患者某指标的均数与标准差s, 甲药1=4.0,s1=0.6;乙药2=5.4, s2=0.8。 试估计两总体均数的差值。本例 n1=40, n2=38; 1=4.0, 2=5.4; s1=0.6,s2 =0.8。
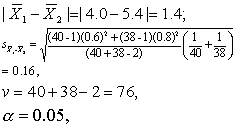
查t界值表,t0.05,76=1.99,
(1.4-1.99×0.16,1.4+1.99×0.16)=(1.1,1.7)。
两总体均数差值的点估计为1.4,95%可信区间为1.1~1.7。
☚ 总体标准化率估计 总体几何均数估计 ☛
- 认票不认人是什么意思
- 认缴资本税是什么意思
- 认罪服法心理是什么意思
- 认罪答辩是什么意思
- 认股书是什么意思
- 认股书是什么意思
- 认股权是什么意思
- 认股权证是什么意思
- 认股权证是什么意思
- 认股权证是什么意思
- 认股权证是什么意思
- 认股特权是什么意思
- 认股证是什么意思
- 认股证书是什么意思
- 认股证价值是什么意思
- 认股证套头交易是什么意思
- 认药学是什么意思
- 认许资产是什么意思
- 认证是什么意思
- 认证是什么意思
- 认证是什么意思
- 认证是什么意思
- 认证制度是什么意思
- 认证制度是什么意思
- 认证标志是什么意思
- 认证标志是什么意思
- 认证标志是什么意思
- 认证检验机构是什么意思
- 认证证书是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识是什么意思
- 认识与实践的统一是什么意思
- 认识与所知是什么意思
- 认识与自由是什么意思
- 认识世界和改造世界是什么意思
- 认识你自己是什么意思
- 认识你自己是什么意思
- 认识你自己是什么意思
- 认识发展的总规律是什么意思
- 认识和实践是什么意思
- 认识四阶段论是什么意思
- 认识型是什么意思
- 认识媒介文化——社会理论与大众传播是什么意思
- 认识对象是什么意思
- 认识方法是什么意思
- 认识时滞是什么意思
- 认识模型是什么意思
- 认识活动论是什么意思
- 认识的主体是什么意思
- 认识的四等级是什么意思
- 认识的客体是什么意思
- 认识的片面性是什么意思
- 认识的螺旋曲线是什么意思