基因定位mapping
主要指确定基因所在的染色体及其在染色体上的位置。基因定位的方法,因生物类型的特点不同而异,大致可分为染色体水平上和分子水平上的基因定位两类。
高等动、植物的基因定位
三点测验法 1911年摩尔根(T. H.Morgan)提出把交换值作为度量基因间的遗传距离。1913年斯特蒂文特(A.H.Sturtevant)首先用于果蝇的基因定位。三点测验法是用一次杂交和一次测交确定3对基因的位置。例如玉米籽粒凹陷、非糯、有色的品种(sh++/sh++)与饱满、糯性、无色的品种(+wxc/+wxc)杂交,F1(sh++/+wxc)与隐性品种(shwxc/shwxc)测交,所得测交子代的表型(见表1)。三基因之间的交换值可计算如下:
表1 玉米的三点测验
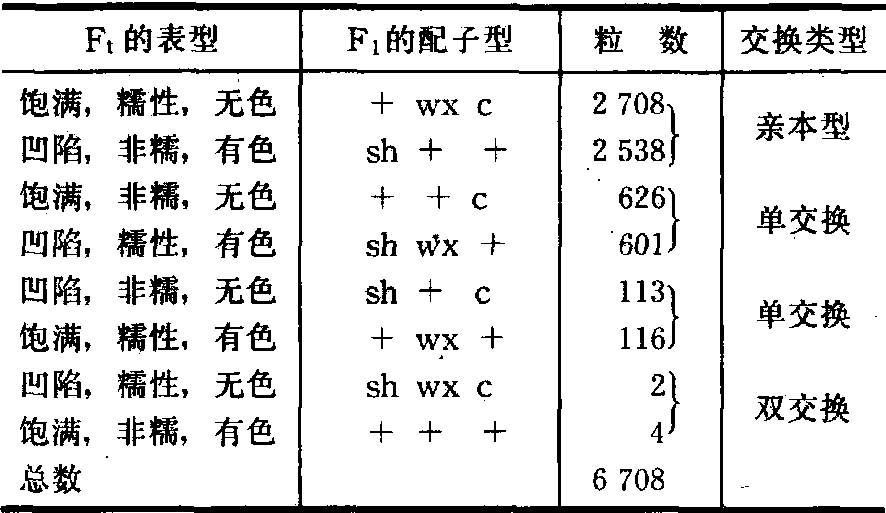
sh和wx的重组率=(626+601+4+2)/6708
=18.4%;
sh和c的重组率=(113+116+2+4)/6708
=3.5%;
wx和c的重组率=(626+601+113+116)/6 708
=21.7%
由此可知sh在三个基因中居中。wx和c的重组率21.7%,须加上双交换值2×(2+4)/6 708=0.00178,约等于21.9%。这样可以确定三个基因在染色体上的相对位置为:
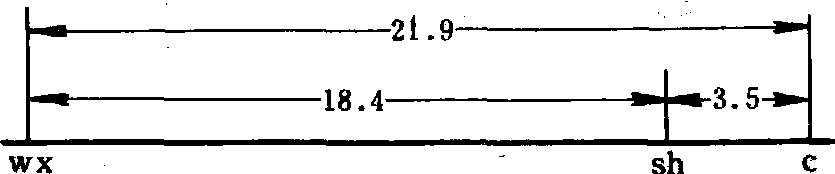
缺失畸变定位 1931年美国细胞遗传学家麦克林托克(B.McClintock)用玉米染色体缺失畸变创造了两种基因定位法。❶用X射线处理纯合显性紫株(P1 P1)的花粉诱发缺失畸变,再给绿株(pl pl)授粉,在734的F1株中发现2株绿苗。经细胞学检查,绿株的第6染色体缺失了长臂的外段,由此可知pl基因位于第6染色体的长臂外侧。绿株是由于F1丢失了显性基因,造成假显性现象的结果。
❷用隐性个体做母本,缺失杂合体做父本,缺失染色体的雄配子不能参与受精,子代表现显性的必为未交换的类型,即亲本型,表现隐性的必为重组型; 如果知道缺失位点,就可对此基因进行定位。玉米和番茄的许多基因就是用上述两种方法定位的。果蝇的唾腺染色体不同节段有标记横纹,根据缺失横纹的细胞学观察和同源染色体上隐性基因的遗传表现,能够准确定出基因在染色体上的具体位置,绘出细胞学图。
缺失了一条臂的端着丝粒染色体在异源多倍体(如小麦,陆地棉)的基因定位中有特殊价值。其方法类似上述第二种。因为已知缺失位点是着丝粒,交换值表示所测基因与着丝粒的遗传距离。
易位体定位 非同源染色体相互易位改变了原有基因的连锁关系。利用表型遗传学鉴定和染色体易位的细胞学观察,可以确定基因或连锁群所在的染色体。例如玉米的yg2(黄绿苗),sh(籽粒凹陷)、wx(糯性)和V1(淡绿苗)为一连锁群;bm(叶中脉褐色)和pr(红色糊粉层)为另一连锁群。确定两个连锁群所在的染色体,一般利用一系列带标记基因的易位系进行测验。结果在对T5-9(第5和第9染色体的易位)易位系的测验中,上述基因皆表现连锁;在对T2-5易位系的测验中,只与pr基因表现连锁。yg2、sh、wx和V1四个基因位于第9染色体上; bm和Pr两个基因位于第5染色体上。同理,可以对新发现的突变基因进行易位系测验,从而确定新的突变基因所在的染色体。由于玉米染色体有清楚可辨的染色质颗粒,容易通过细胞学观察确定易位所涉及的染色体。其他生物需要通过显带技术来确定易位涉及的染色体。
利用易位系确定基因的位点。由于易位杂合体表现部分不育或半不育,可以把易位染色体的易位点看作显性基因T,把正常染色体相应位点看作隐性基因t,进行两点或三点测验。通常用具有杂合基因型的易位杂合体与隐性正常个体测交。例如玉米易位杂合体T1-2与不同的测交种所做的几个测交结果(表2)。
表2 玉米的易位体测验
| 测 交 组 合 | 全育(t) | 半不育(T) | 交换值 (%) | ||
| 显性 | 隐性 | 显性 | 隐性 | ||
| Tp/tP×ttpp TF1/tf1×ttf1f1 TAn1/tan1×ttan1an1 TLg1/tlg1×ttlg1lg1 TV4/tv4×ttv4v4 | 112 25 9 144 43 | 111 281 219 123 229 | 135 350 249 177 289 | 120 26 5 139 27 | 51.50 7.48 2.90 48.13 11.90 |
an1距易位点T最近,只有2.9个遗传单位,而P和lg1距易位点T较远,分别为51.5和48.13个遗传单位。根据其他易位体的测验得知P(果皮红色)、an1(雌穗上长雄花),f1(细条纹叶)三个基因位于第1染色体上;lg1(无叶舌)和v4(淡绿苗)位于第2染色体上。因此T1-2的遗传图为:

单体测验 用隐性个体与表现显性的一系列单体分别杂交,F1群体均表现显性的组合,所测基因不在该单体染色体上; F1群体中单体表现隐性,双体表现显性的组合,所测基因在该单体染色体上。
三体测验 用隐性个体与表现显性的一系列三体分别杂交,F1再与隐性亲本回交。若回交后代呈1 显性、1隐性分离,所测基因不在该三体染色体上; 如发生偏离,所测基因在该三体染色体上。
此外,也可用缺体确定基因所在的染色体。用非整倍体进行基因定位,特别有利于确定异源多倍体生物的异位同效基因所在的染色体。
真菌的基因定位
着丝粒定位法 1932年微生物遗传学家林格伦(C.C.Lindgreen)首创。例如将粗糙脉孢霉的赖氨酸缺陷型(lys-)与野生型(lys+)杂交,F1子囊中的孢子可出现六种排列方式: ++++----,----++++,++--++--,--++--++,++----++和--++++--。前两种为亲本型,是第一次分裂分离的结果; 后四种是重组型,是第二次分裂分离的结果 (图1)。其交换值计算为:
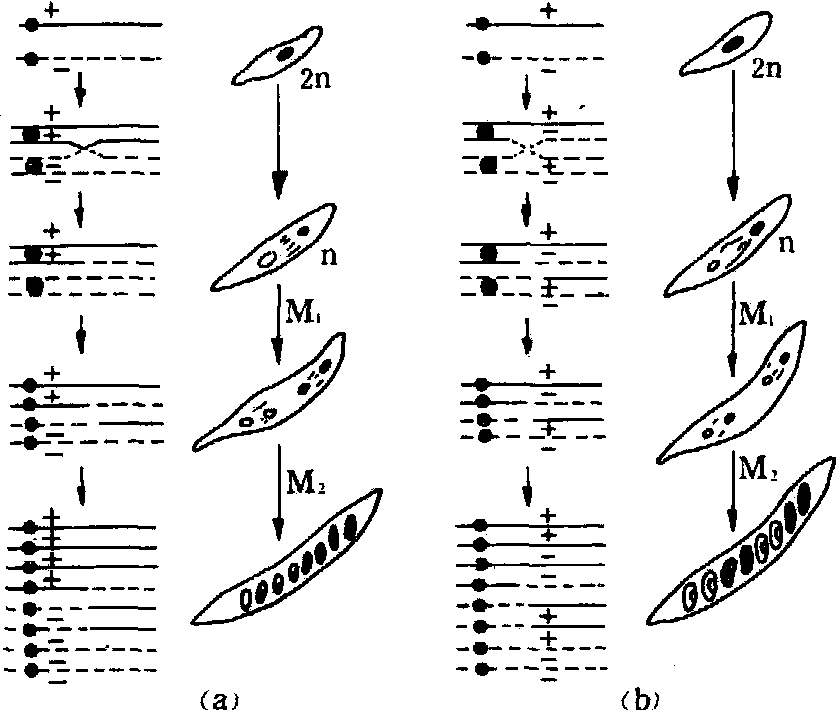
图 1 粗糙脉孢霉交换示意
(a)非交换型(交换未发生在着丝点与+/-基因之间)(b)交换型(交换发生在着丝点与+/-基因之间)

交换值为基因距着丝粒的遗传距离。小于33.3%的为连锁,大于33.3%是独立遗传。因为在四分孢子的排列顺序中,如果“+”排在第一位,另一个“+”排在第二位的机会是1/3,“-”排在第二位的机会是2/3,后者产生重组型,即66.6%的子囊为重组型,所以最大交换值为66.6%÷2=33.3%。
如果有两个突变基因,可进行三点的着丝粒定位。1956年豪(H.B.Howe)用粗糙脉孢霉交配型A缓慢生长 (v)菌株与交配型a正常生长(v+)菌株杂交,子囊的分离归纳为七种类型(表3)。
表3 链孢霉的连锁遗传
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 分 离 类 型 | Av | Av+ | Av | Av | Av | Av+ | Av |
| Av | Av+ | Av+ | av+ | av+ | av | av+ | |
| av+ | av | av | Av | Av | Av+ | Av+ | |
| av+ | av | av+ | av | av+ | av | av | |
| 子囊数 | 888 | 1 | 126 | 128 | 5 | 3 | 10 |
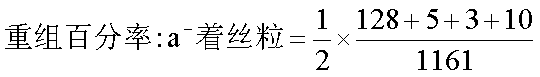
a与v位于同一染色体上的着丝粒两侧。a-v的重组率11.71%小于6.2%+6.287%,是由于发生了双线双交换的缘故。三点的遗传图为:
![]()
如果a,v的重组率是50%,说明不属于同一染色体。
四分体分析 子囊中四分孢子顺序排列的链孢霉和无顺序排列的酵母菌均适用。林德伯格用维生素B6缺陷型(py)和维生素B1缺陷型(th)的酵母菌py th与正常菌株py+th+杂交,观察子代子囊孢子总数为300,其中py+th和py th+两类重组型孢子为208。重组
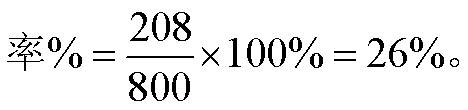
单倍体化定位法 两种构巢曲霉品系的单倍体菌丝可联结产生异核体,偶而异核可融合成杂合的二倍体核。这种二倍体极不稳定,在有丝分裂过程中常随机的丢失染色体。经过多次有丝分裂染色体逐条丢失直至只剩下一个染色体组,而成为单倍体。如果显性基因丢失,则半合的隐性基因得以表达。两个或两个以上非等位基因在多次单倍体化过程中总是伴随在一起,即可证明这些基因位于同一条染色体上。
基因转变定位法 一个基因内部不同突变位点发生基因转变是有极性的,远端的比近端的转变频率高;位点相距愈近共转变频率愈高(见基因转变)。可以利用此特点确定基因内不同突变位点的位置。福格尔(S.Fogel)等用酵母菌四个缺陷型的杂交试验结果(见表4)。
表4 酵母菌四个精氨酸缺陷型的杂交试验
| 杂交组合 | arg4×arg17 | arg1×arg2 | arg2×arg17 |
| 分析的子囊数 近端的基因转变数 远端的基因转变数 共转变数 突变位点间的核苷 酸对 | 697 8 38 3 1 060 | 502 8 21 23 520 | 544 4 5 27 128 |

细菌和病毒的基因定位
并发转导法 细菌不同基因的并发转导(见转导)频率愈高遗传距离愈近,因此可以利用并发转导率进行细菌的基因定位。例如用普遍性转导噬菌体P1侵染带有leu+(亮氨酸)、thr+(苏氨酸)和azir (抗叠氯化钠)三个基因的大肠杆菌作基因供体,再用释放的P1噬菌体侵染leu-、thr-、azis菌株(受体)。将受体细菌分别进行特定培养,以便测定基因的并发转导率。如将它培养在不含叠氯化钠而加有苏氨酸的基本培养基上,于是leu成为选择的标记基因,然后对leu+的细胞再进一步进行选择培养,以测试它和thr+或azir的并发转导频率。同理进行其他选择标记基因的试验,结果如下(见表5):
表5 P1噬菌体对大肠杆菌基因的并发转导
| 实 验 | 选择的标记基因 | 未选择的标记基因 |
| 1 2 3 | leu+ thr+ leu+thr+ | 50%azir,2%thr+ 3%leu+, 0azir 0azir |
综合三个实验的结果,可以得出三个基因的顺序为: azi—leu—thr。
由于P1噬菌体能转导大肠杆菌二分钟图距的一段DNA,可以用下述公式计算出三点的距离。

中断杂交法 在细菌接合中,供体(Hfr菌株)的染色体进入受体(F-菌株)是成直线的。根据这一原理可采用中断杂交法测定供体染色体上各基因进入受体的先后顺序及时间间隔进行基因定位。将多标记的F-菌株和Hfr菌株的细胞混合培养,每隔一定时间取少量样品进行剧烈搅拌以便中断杂交,然后在供体Hfr菌株不能生长的培养基上培养,所出现有Hfr菌株性状的菌落就是该基因进入F-菌株的标志,进入的时间就是该基因的位点。一个时间单位(分钟)大约相当于20%的重组率。供体染色体转移的原点是F因子和染色体的接合点,由于F因子以不同方向和不同位点整合在染色体上而形成了不同的Hfr菌株。用一系列的Hfr菌株与F-菌株进行中断杂交就可绘制细菌的遗传连锁图。目前应用中断杂交法已将大肠杆菌的约1 000个基因定位在环状染色体上。
缺失定位法 多位置的突变型相当于缺失一部分染色体,也称缺失突变型。利用这些缺失突变菌株确定细菌或噬菌体的基因位置。例如确定沙门氏菌(Sal-monella)某一新的组氨酸突变型的位置,先将它与各种缺失突变型分别杂交,如果突变位点在某缺失突变型缺失染色体内,不能产生野生型重组型; 如果在缺失染色体区段外,能产生野生重组型。例如,假定新突变型不能跟22、2226、2253、644、2652和2614缺失突变型产生野生重组型,而能跟其余的缺失突变型产生野生重组型,新突变的位置在组氨酸B(hisB)中(图2)。再与hisB中其他点突变杂交,可以进一步确定新突变的位点。这样不仅可以进行基因定位,还可确定基因内的不同突变位点,进行基因精细结构分析。
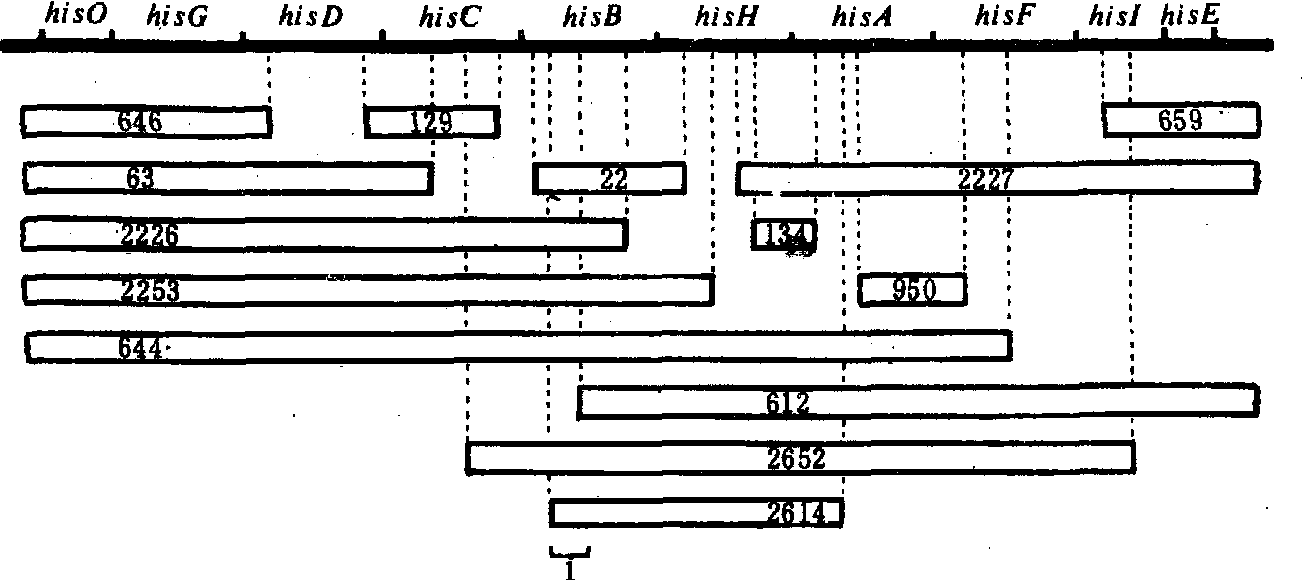
图 2 缺失定位示意图
双重感染法 (见连锁与交换)。
分子杂交法 (见分子杂交技术)。
用体细胞杂交也可以进行基因定位。例如,在离体条件下将人和小家鼠的体细胞杂交,杂种细胞在有丝分裂中会逐步丢失人的染色体。将只保留有一条或几条人的染色体的杂种细胞分别克隆,用选择性培养基培养这些杂种细胞株,可以进行基因定位。例如5-溴脱氧尿嘧啶(BUDR)能杀死含胸腺核苷激酶的细胞,而小家鼠缺少这种酶。用BUDR培养杂种株时,含有第17号人类染色体的杂种株不能存活,可以确定控制胸腺核苷激酶的基因位于第17染色体上。
基因定位mapping
测定基因所在的连锁群或染色体,以及连锁基因的排列顺序和彼此间的距离。也包括对一个基因内不同突变位点的测定。有多种测定方法。高等动植物常用三点测验,也可用染色体结构变异(如缺失或易位杂合体等)和数目变异(如单体、缺体及三体等)的品系进行基因定位,以与三点测验相互补充,尤其在异源多倍体植物中应用较多。子囊菌多用四分子分析法。细菌应用中断杂交、并发性导及并发转导等方法。噬菌体多采用双重感染法。随着分子遗传学的发展,可用分子杂交和DNA重组技术进行更精确的基因定位。此外,应用多标记的不同菌株共转导法、噬菌体的缺失法以及基因转变的梯度定位法,还可测定基因内不同突变位点的精细结构。在基因定位中一般是以交换值(重组率)和时间(用于细菌)作为相对的遗传单位。可辩认染色体细微标志的果蝇细胞学图和原核生物的物理图谱等,显示的则是真实位置和绝对的距离。通过基因定位可以绘制连锁遗传图,还可了解基因的功能和不同基因间的关系。在实践中,有助于杂交方案的制定,有目标地更换染色体的工程实施,及对某些遗传病的鉴别和防治等。
基因定位gene mapping
系指基因位于染色体的固定区域、位点而言。染色体是基因的载体,由于染色体不同显带方法的出现,各染色体的显带已经明确。因此通过各种生理性、疾病性、实验性等手段已能证实某些区带或某位点有何种基因。其中在电镜下观察由于染色体易位、缺失、倒位、插入等改变而出现的相应表现,也可知某些功能基因的位置;应用原位杂交技术则可以测定特异的DNA和RNA的顺序,更有利于基因定位;通过遗传疾病家系染色体分析不但可以测定基因位置而且还可以了解基因功能情况。基因定位为绘制基因图打下了基础。
基因定位
对基因所属连锁群或染色体的测定以及基因在染色体上的位置的测定。它有助于了解基因的功能及染色体的行为。方法有系谱分析法、四分体分析法、连锁群法、三点测验法、体细胞杂交法等。
基因定位
基因定位就是通过适当方法把每个发现了的基因在特定染色体上的位点准确地标定下来; 并且根据大量的基因定位数据,把每一条染色体上已发现的基因位点绘制成基因图,这一程序叫做基因制图。
基因定位原理和方法论 是由摩尔根和其研究小组奠定的。早在1911~1913年,他们采用果蝇连锁性状群进行杂交,发现孙代中两群等位基因之间的重组率(又称交换率)大小不同(见“连锁与交换”)。例如黄体、白眼和二裂脉三个基因同属于性连锁群,同为隐性。实验表明,黄体和白眼二基因之间的重组率为1.2%; 白眼和二裂脉二基因之间的重组率为3.5%; 黄体和二裂脉的重组率为4.7%。摩尔根等设想,两对连锁基因相距越近,重组率应该越小,重组率的大小可以反映两对基因之间距离的远近。事实上,黄体基因-二裂脉基因的重组值,等于黄体基因-白眼基因与白眼基因-二裂脉基因两者重组值之和; 在三个重组值当中,已测定两个重组值,便可推算第三个重组值。这种加减数字关系提示了三个基因是呈直线排列的,三者排列顺序是黄体基因-白眼基因-二裂脉基因,三者相互间的距离表现为其重组率。1919年,Haldane把一个连锁群总长当作一个摩尔根单位,简称摩(M或mo),相当于100%的重组率; 10%的重组率称为一分摩(dM或dmo); 1%的重组率称为一厘摩(cM或cmo)。
摩尔根等根据大量杂交实

图1 果蝇基因的连锁图绘制原理示意
验中的重组型数据,确定了果蝇四个连锁群里诸基因的相对位置和相互距离,绘制了果蝇基因的连锁图,或称遗传图。黑腹果蝇遗传图经受了以后细胞学特别是果蝇唾腺染色体的检验,证实其基因直线排列顺序完全正确。果蝇幼虫的唾腺细胞含有巨染色体。比普通细胞的染色体约大100到150倍,果蝇幼虫的染色体组共有5000多条横带,染色很深,表现DNA染色反应。根据各带的形状、粗细、染色深浅和分布疏密等特点,可以鉴别每一条染色体上的每个片段,便于进行基因定位研究。1925年,Sturterant根据杂交结果,断定棒眼基因位于X染色体上,其位点之长倍于正常圆眼基因。1936年,Bridges在唾腺染色体上证实,正常圆眼果蝇唾腺X染色体上这一片段约有6条带,而在棒眼果蝇X染色体上,这一段却重复了一次,有12条带。细胞学观察完全证实了遗传学的推论(见“连锁和交换”)。其他许多个基因也受到类似的细胞学检查,都引出了同一结论,即这些基因在有关染色体上的排列顺序,和根据重组型百分率所推算的遗传图上的顺序完全符合,不同的只是基因位点之间的距离稍有出入而已。用染色体结构畸变所得出的连锁关系的改变,结合唾腺巨染色体的观察所确定的果蝇各染色体上所具有的基因位点和排列顺序,可以制订染色体图,或称细胞学图。当果蝇基因定位研究达到高峰时,人类基因定位研究还处于萌芽状态。根据性连锁遗传的特点,很容易推断红绿色盲和血友病A型的基因位于X染色体上。人们还根据某些性状在几代间联合遗传的现象找到了这些基因的连锁关系。例如,Mohr(1954)确定了Lutheran血型基因和ABO血型“分泌者”基因是连锁的。这是常染色体连锁基因的第一例。以后陆续发现了Rh血型基因同椭圆红细胞增多症基因以及ABO血型基因同指甲-髌发育不全综合征基因的连锁关系。但是,单凭两个位点的连锁还不能肯定位点究竟在哪条染色体上,还必须根据遗传性状同染色体特定片段的共存关系进行基因定位。例如1963年发现双侧视网膜母细胞瘤与D组某号染色体(以后证明是13号)长臂缺失有关,从而提示有关基因位于13号染色体长臂上。总之,人类基因定位的进展还是比较迟缓的,一直到体细胞遗传学特别是体细胞融合技术出现以后,才迅速开展起来。人类基因图的绘制不仅对认识人类遗传物质的精细结构及其发展和进化有一定意义,对人类遗传病和恶性肿瘤的发病原因、预防和治疗都将起重要的作用。
人类基因图的绘制方法 有系谱分析法,体细胞杂交法,RNA(DNA)原位杂交法,以及Lepore法,基因剂量法等。
(1) 系谱分析法: 这是经典的连锁群分析法,如X染色体上和常染色体上的基因定位是基因连锁分析。有些遗传性状如色盲、血友病等是X连锁遗传,这种遗传方式很容易被人识别。X连锁隐性疾病一般只有男性才发病,如外祖父有病,母亲表型正常,外孙中有一半的机会发病。因此只要通过家系调查就可把决定该疾病的基因定位在X染色体上,如两个基因位点已定位在X染色体上, 还可根据双因子杂种母亲两对性状在儿子中间出现重组体的比例,推算出两个有关基因之间的距离。
常染色体上的基因定位比较困难,一般从分析基因连锁群入手,再根据基因之间的重组率来进行定位。到目前为止,因系谱分析方法和体细胞杂交的方法,已有100多个基因定位在X染色体上,有200多个基因定位在常染色体上。很清楚,已经定位的基因数目只占基因总数的很小一部分,系谱分析法有它严重的局限性,因为家庭成员少,地理分布很散,一个世代的时间太长。要研究两代以上就感到困难。由于这些限制,因此,从1911年把红绿色盲基因第一次定位在X染色体上以来,人类基因制图工作进展不快。体细胞杂交法可以克服上述缺点,推动基因制图,使之取得了巨大进展。
(2) 体细胞杂交法或体细胞融合法: 这是体细胞遗传学领域中重要的技术性进展之一 (见“体细胞遗传学”)。应用体细胞杂交作基因定位,是1967年Weiss和Green开始的。种内细胞杂交 (即杂种的两个亲本属于同一物种)的特点是染色体数目稳定,往往含有原来两个亲本的染色体组。种间杂种细胞(亲本细胞属于不同物种,如小鼠细胞与人体细胞杂交)长期离体培养时,出现染色体丢失的明显趋势,一般只丢失一种亲本的染色体。例如,在小鼠与人体细胞杂交后,杂种细胞选择性地丢失人的染色体;随着时间的消逝,杂种细胞含有鼠的全套染色体,同时只含有一条或少数几条人的染色体。如果在杂种细胞中只剩下一条人的特定染色体,而且这个细胞还能合成人类所特有的蛋白质,那么就可以得出结论:决定这个蛋白质的结构基因刚好就位于杂种中的这条唯一残存的人类染色体上。由于种间细胞自发融合的频率很低,所以需加入灭活的仙台病毒,以提高融合频率。从大量细胞群体中,选出杂种细胞的步骤是:首先采用具有某种代谢缺陷型的亲本细胞,以人-鼠体细胞杂交来说,人的成纤维细胞是次黄嘌呤鸟嘌呤转磷酸核糖基酶缺陷型(HGPRT-),鼠细胞是胸苷激酶缺陷型(TK-)。其次,是用选择培养基,选出两种细胞杂交形成的杂种细胞。在选择培养基上亲本细胞不能繁殖,而只有杂种细胞才能繁殖。如次黄嘌呤-氨基喋呤-胸苷(HAT)选择培养基,其中A为氨基喋呤,能阻断细胞内合成嘌呤和嘧啶,这是核苷酸正常合成过程中所必需的。当A阻断这条主要合成途径时,缺陷型细胞(亲本细胞)就都死亡,因为亲本细胞中缺少HGPRT或TK,就不能走应急通路这条次要途径,即不能利用选择培养基中的次黄嘌呤(H)和胸苷(T)来合成核酸。只有那些种间杂种细胞,由于两种缺陷的互补,是HGPRT+和TK+,因而可以利用培养基中的H和T,尽管A阻断了从头合成核酸的途径,而杂种细胞在HAT培养基上能够正常生长(图2)。对于这样的杂种,有两点十分重要:
❶小鼠的染色体或遗传物质,基本上完整地保留下来,而人的染色体却优先地随机丢失,杂种细胞的染色体数通常是41~55条,少于人和小鼠全套染色体相加的总数86条。所有的小鼠染色体都保留下来;而人的染色体大部分随机丢失,这样,在不同的杂
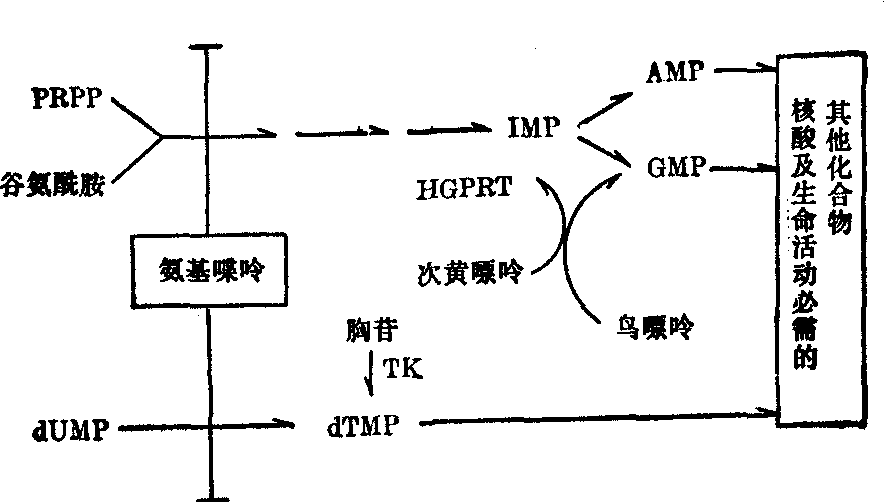
图2 HAT选择系统的生化路线示意图
PRPP 磷酸核糖焦磷酸 IMP 次黄苷酸(肌苷酸)
AMP 腺苷酸 GMP 鸟苷酸
duMP 脱氧尿苷酸 dTMP 脱氧胸苷酸
TK 胸苷激酶 HGPRT 次黄嘌呤鸟嘌呤转磷酸核糖基酶种细胞克隆内残存的人体染色体各不相同。
❷鼠和人的染色体组都是具有功能的,它们的基因能同时表达出来,各自合成相应的蛋白质。两个种的染色体可根据它们的形状、大小和着丝粒位置以及带型而加以识别,从而确定每个杂种细胞克隆中残存的是哪几条人体染色体。此时对照基因产物就可确定某个基因在哪一条染色体上。体细胞杂交进行基因定位的方法还可分为同线法、定位法和划区法。如两个基因或是同时出现或是同时消失,表明它们在同一条染色体上,但不知道究竟在哪一条染色体上,所以称为同线法。定位法是用来确定同线的几个基因位于哪一条染色体上。如要把基因精确地标定在染色体的某一区段,这就要用划区法。
(3) 核酸分子原位杂交法:用同位素标记的特定RNA或特定cDNA直接与细胞中的染色体上有关DNA片段相结合,测定标本中放射性结合的程度和部位,也可以找出这一RNA的基因位点。应用这种原位杂交的方法,已经把18S和28S核糖体RNA(rRNA) 基因定位在13、14、15、21和22号染色体短臂上,至于5SrRNA的基因,则定位在1号染色体长臂远端。
(4) Lepore法:这是用来推测基因位点紧密连锁的一种方法。血红蛋白Lepore是一种异常血红蛋白,它的一条肽链的氨基末端由血红蛋白的δ链构成,其余部分则由β链构成。这说明δ链和β链的基因位点是紧密连锁的。
(5) 基因剂量法: 根据染色体或其个别片段的增多或减少,基因份数也相应地增多或减少。如果用生化方法能够测出某种基因产物的量也随之增减,那么就能将该基因定位在这条增加或缺失的染色体上。或者定位在增加或缺失的某一条带上。
基因定位的方法虽然很多,但基因图主要还是靠系谱法和体细胞杂交法制定的。人类基因的国际性工作会议从1973年开始至今已开过四次,今将第四届会议上已定位的基因资料列于表1~3。
表1 Winnipeg会议(1977)确定的常染色体基因位置(按染色体顺序排列)
| 标 记 名 称 | 标记符号 | 决定标记表型的基因位置 | |
| 染色体* | 区 域** | ||
| 腺病毒12引起染色体变化的位置-1号短臂 腺病毒12引起染色体变化的位置-1号长臂 | AdV-12CMS-1p AdV-12CMS-1q | 1 P 1 P | pter→p36 q42 |
| 腺苷酸激酶 淀粉酶(唾腺) 淀粉酶(胰腺) | AK2 AMY1 AMY2 | 1 1 1 | pter→p32 p p |
| 抗凝血酶Ⅲ | AT-3 | 1 T | |
| 白内障,粉碎性小带(Fy连锁) | Cae | 1 | pter→p32 |
| 胆碱酯酶(血清)-1 Dombrock血型 Duffy血型 | E1 Do Fy | 1 T 1 T 1 | |
| 椭圆红细胞增多症(Rh连锁) 烯醇酶-1 α-L-岩藻糖苷酶 延胡索酸水合酶 | El1 ENO-1 αFUC FH | 1 1 1 1 | p pter→p36 p32→p34 q42→qter |
| 葡萄糖脱氢酶 鸟苷酸激酶-1 肽酶-C 葡萄糖磷酸变位酶-1 磷酸葡糖酸脱氢酶 | GDH GUK-1 PEP-C PGM-1 PGD | 1 P 1 1 1 1 | pter→p32 q32→q42 q25或q42 p21→p34 p34→pter |
| 视网膜色素沉着 | RP | 1 P | |
| Rhesus血型 5S RNA 坐位 | Rh RN5S | 1 1 | pter→p32 q42→q43 |
| Scianna血型 铁传递蛋白 | Sc Tf | 1 P 1 T | |
| 尿苷二磷酸葡糖焦磷酸化酶-1 尿苷-磷酸激酶 | UGPP1 UMPK | 1 1 | q21→q23 p32 |
| 酸性磷酸酶-1 | ACP1 | 2 | p23 |
| 芳基碳氢化合物羟化酶 | AHH | 2 P | |
| 半乳糖+活性因子 干扰素-1 | Gal+-Act If-1 | 2 P 2 P | p11→p22 |
| 异柠檬酸脱氢酶(水溶性) 苹果酸脱氢酶,NAD(水溶性) | IDHs MDHs | 2 2 | q11或q32→qter pter→p23 |
| 尿基二磷酸葡糖焦磷酸化酶-2 | UGPP2 | 2 P | |
| 谷胱甘肽过氧物酶-1 疱疹病毒敏感性(1型) 温度敏感补体 | GPX1 HSV-1 AF8ts+ | 3或21 I 3 P 3 P | |
| 白蛋白 血型特异性成分 MNSs血型 | Alb GC MN,Ss | 4 P 4 P 4 P | q11→q13 q11→q13 |
| 肽酶-S 葡糖磷酸变位酶-2 | PEPS PGM2 | 4 4 | pter→q21 p14→q21 |
| 硬胼胝症 | Tys | 4 P | |
| 抗病毒状态的抑制调节 芳基硫酸酯酶B | AVSrr ARSB | 5 P 5 P | p |
| 白喉毒素敏感性 | DTS | 5 | q15→qter |
(续表)
| 标记名称 | 标记符号 | 决定标记表型的基因位置 | |
| 染色体* | 区 域** | ||
| 已糖胺酶B | HEXB | 5 | cen→q13 |
| 干扰素-2 亮氨酰(基)-tRNA合成酶 | If-2 LEURS | 5 P 5 P | |
| 肾上腺增生(21-羟化酶缺失) Chido 血型 | CAH-21 Ch | 6 6 | p21→p23 p21→p23 |
| 补体成分-2 补体成分-3b受体 补体成分-3d受体 | C2 C3bR C3dR | 6 P 6 P 6 P | p21→p23 |
| 补体成分-4 补体成分-8 乙二醛酶-1 人类白细胞抗原 苹果酸酶(水溶性) | C4 C8 GLO-1 HLA-A,B,C,D MES | 6 P 6 T 6 6 6 | p21→p23 p21→p23 p23→p21 p21→p23 q12→q15 |
| 猴红细胞受体 橄榄桥脑小脑萎缩 胃蛋白酶原(同功酶-5) | MRBC OPCA-1 Pg | 6 P 6 P 6 T | |
| 葡糖磷酸变位酶-3 | PGM3 | 6 | p21→qter |
| 血纤维蛋白溶酶原激活剂 | PA | 6 P | |
| 备解素因子B | Bf | 6 | p21→p23 |
| Ragweed敏感性 Rodgers血型 过氧化物岐化酶(线粒体) 表面抗原6 | RWS Rg SODM SA6 | 6 P 6 P 6 6 | p21→p23 p21→p23 q21 |
| 凝集团子Ⅻ(Hageman) Colton血型 | HAF Co | 7 P 7 P | q35 |
| β葡糖苷酸酶 | βGUS | 7 | p13→cen或cen→q21 |
| H4组蛋白 羟酰辅酶A脱氢酶 免疫球蛋白Kappa链标记(与JK连锁) Kidd血型 | H4 HADH Km JK | 7 P 7 P 7 P 7 P | |
| 苹果酸脱氢酶,NAD(线粒体) | MDHM | 7 | p22→q22 |
| 嗜中性趋化反应 表面抗原7 | NCR SA7 | 7 P 7 P | |
| SV40-位点1*** 尿苷磷酸化酶 | SV-40-1 UP | 7 P 7 P | q |
| 凝集因子V11 | F7r | 8 P | |
| 谷胱甘肽还原酶 | GSR | 8 | p21 |
| ABO血型 乌头酸酶(水溶性) 腺苷酸激酶-1 腺苷酸激酶-3 | ABO ACONS AK1 AK3 | 9 9 9 9 | q34 pter→p11 q34 pter→p11 |
| 精氨酸琥珀酸合成酶 质膜-DNA连合 Kell血型 | ASS cmDNA K | 9 P 9 P 7T或9T | |
| 指甲-膑骨发育不全综合征 | Np(NP-1) | 9 | q34 |
(续表)
| 标记名称 | 标记符号 | 决定标记表型的基因位置 | |
| 染色体* | 区域** | ||
| 白额发异色眼综合征(Ⅰ型) 着色性干皮病(埃及型) 腺苷激酶 膜外蛋白(MW130,000) | WS XP-E ADK EMP-130 | 9 T 9 T 10 P 10 P | |
| 谷氨酸草酰乙酸转氨酶(水溶性) | GOTS | 10 | q24→q26 |
| 谷氨酸-α-半醛合成酶 | GSAS | 10 P | |
| 己糖激酶-1 | HK1 | 10 | pter→q24 |
| 多核细胞增生症启动子 | FUSE | 10 P | |
| 焦磷酸酶(无机) 酸性磷酸酶-2 酯酶-A4 乳酸脱氢酶-A | PP ACP2 ESA4 LDHA | 10 11 11 11 | pter→q24 p12→cen cen→q22 p12.3→p12.8 |
| 致死抗原 | ALa-1 ALa-2 ALa-3 | 11 P 11 P 11 P | pter→p13 q13→qter pter→p13 |
| 表面抗原1 Wilms肿瘤-AGR三价元素 | SA-1 WAGR | 11 P 11 p | p |
| 柠檬酸合成酶 烯醇酶-2 | CS ENO-2 | 12 12 | |
| 甘油醛-3-磷酸脱氢酶 乳酸脱氢酶-B 肽酶B | GAPDH LDHB PEPB | 12 12 12 | pter→p12.2 p12.1→p12.2 q21 |
| 丝氨酸羟甲基转移酶 表面抗原12 | SHMT SA12 | 12 P 12 P | pter→q14 |
| 磷酸丙糖异构酶-1 | TPI-1 | 12 | pter→p12.2 |
| 磷酸丙糖异构酶-2 | TPI-2 | 12 P | |
| 酯酶-D | ESD | 13 | q3→qter |
| 脂蛋白 | Lp | 13 P | |
| 视网膜母细胞瘤 核糖体RNA | RB RNr | 13 13 | q p12 |
| 膜外蛋白(MW195,000) | EMP-195 | 14 P | |
| 核糖体RNA 核苷磷酸化酶 色氨酰(基)-tRNA合成酶 | RNr NP TRPRS | 14 14 14 | p12 q12→q20 q21→qter |
| 己糖胺酶A 异柠檬酸脱氢酶(线粒体) 甘露糖磷酸异构酶 | HEXA IDHm MPI | 15 15 15 | q22→qter q21→qter q22→qter |
| α-甘露糖苷酶A β2-小球蛋白 丙酮酸激酶 核糖体RNA 腺嘌呤磷酸核苷转移酶 | MANA β2m (M2)(PKM2) rRN APRT | 15 P 15 15 15 16 | q11→qter q22→qter q22→qter p12 q |
(续表)
| 标记名称 | 标记符号 | 决定标记表型的基因位置 | |
| 染色体* | 区 域** | ||
| 抗病毒调节因子 | AVSr | 16 P? | |
| 胆碱酯酶(血清)-2 α-结合珠蛋白 | E2 αHp | 16 P 16 | cen→q22 cen→q22 |
| 谷氨酸草酰乙酸转氨酶(线粒体) 干扰素调节因子 | GOTM Ifr | 16 P 16 P | |
| 卵磷脂-胆固醇转酰酶 | LCAT | 16 | cen→q22 |
| 胸腺嘧啶核苷激酶(线粒体) 腺病毒5T-抗原 | TKM AdV-5T | 16 P 17 P | |
| 腺病毒12引起染色体变化的位置-17号 半乳糖激酶 | AdV-12CMS-17 GALK | 17 P 17 | q21→q22 q21→q22 |
| 表面抗原(17号染色体) SV40位点2**** | SA17 SV40-2 | 17 P 17 P | |
| 胸腺嘧啶核苷激酶(水溶性) | TKS | 17 | q21→q22 |
| 线毛膜促性腺激素 | HCG | 18 P | |
| 肽酶A | PEPA | 18 | q23→qter |
| Echo11敏感性 葡糖磷酸异构酶 α-甘露糖苷酶-B(溶酶体) 肽酶D 小儿麻痹病毒敏感性 | E11s GPI MANB PEPD pVS | 19 P 19 19 19 19 | q pter→q13 pter→p13 |
| 腺苷脱氨酶 | ADA | 20 | p11→qter |
| 链甾醇→胆固醇的酶 次黄苷三磷酸酶 干扰素受体 | DCE ITP IfRec | 20 P 20 21 | |
| 苷氨酰胺核苷酸合成酶 | GARS | 21 P | |
| 核糖体RNA 过氧化物岐化酶(水溶性) 乌头酸酶(线粒体) | RNr SODS ACONM | 21 21 22 | p12 q22 |
| 芳基硫酸酯酶 心肌黄酶 | ARSA DIA,NADH | 22 P 22 P | |
| 核糖体RNA | RNr | 22 | p12 |
* 暂定的染色体为“P”,推测的染色体为“T”,各实验室结果不一致的为“I”。
** 代表最小,结果最一致的区域。
*** 包括SV40-T抗原,SV40-I插入位点,SV40-TR转化位点,SV40-TU以及SV40-TSTA肿瘤特异性移植抗原。
**** 同SV40位点1所包括的各位点,即SV40-T,SV40-I,SV40-TR,SV40-TU以及SV40-TSTA。
表2 Winnipeg会议上定位在性染色体上的基因(只列出用体细胞杂交法检出的位点,更详细的资料可参阅Mckusick,1978*)
| 标 记 名 称 | 标记符号 | 决定标记表型的基因位置 | |
| 染色体 | 区 域 | ||
| 白化症(眼睛) 抗血友病球蛋白A(第Ⅷ因子) 抗血友病球蛋白B(第Ⅸ因子) | OA Hem-A Hem-B | X X X | q |
| Becker’s肌营养不良 色盲(deutan) 色盲(protan) α-半乳糖苷酶 葡糖-6-磷酸脱氢酶 次黄嘌呤转磷酸核糖基酶 Kell血型前体 α2-巨球蛋白 智力迟缓 | MDB cbD cbP αGAL G6PD HPRT XK Xm MR | X X X X X X X X X | q q q q22→q24 q26→qter q26→qter |
| 核RNA-1 鸟氨酸转羧酶 | nRNA-1 OTC | X P X | |
| 磷酸甘油酸激酶 磷酸化酶激酶 | PGK PHK | X X | q13 |
| 视网膜裂洞 表面X抗原 酪氨酸转氨酶调节因子 着色性干皮病 Xg血型 | RS SAX-1,2,3 TATr XP Xg | X X X X X | q |
| H-Y抗原(雄性特有) | H-Y | Y | |
* Mckusick,VA,1978 Mendelian inheritance in man,5th. Ed.(Johns Hopkins University Press,Baltimore)
表3 Winnipeg会议发表的未确切定位的常染色体基因
| 标 记 名 称 | 标记符号 | 可能定位的染色体 |
| α-抗胰蛋白酶 Baboon M7病毒感染 胶原蛋白(1型) 酯酶激活剂 甲酰甘氨酰胺核苷酸转氨酶 半乳糖-1-磷酸尿苷转移酶 β-半乳糖苷酶 血红蛋白α 血红蛋白β 免疫球蛋白α链标记 球形红细胞症 | Pi Bevi CoL1 Es-Act FGRAT GALT βGAL Hbα Hbβ A2M SPH-1 | 6,8 6,19I 7,17I 4,5P 4,5P 2,3,9I 3,22I 2,4,16I,5? 2,4,C群或11I 6,8 8,12 |
- 药筒是什么意思
- 药筒分装药是什么意思
- 药筒拔法是什么意思
- 药筒法是什么意思
- 药筛是什么意思
- 药箭是什么意思
- 药箭制作是什么意思
- 药箭毒气方是什么意思
- 药箭镞毒方是什么意思
- 药箱是什么意思
- 药篓子是什么意思
- 药簏是什么意思
- 药粉是什么意思
- 药粉绢是什么意思
- 药粕是什么意思
- 药粥是什么意思
- 药糊是什么意思
- 药纱布是什么意思
- 药线是什么意思
- 药线引流是什么意思
- 药线点灸疗法是什么意思
- 药线疗法是什么意思
- 药给烧是什么意思
- 药缤吟稿是什么意思
- 药罐是什么意思
- 药罐头是什么意思
- 药罐子是什么意思
- 药罐子里的枣子是什么意思
- 药罐法是什么意思
- 药罐罐是什么意思
- 药罐里放糖精——和(何)苦是什么意思
- 药罗葛是什么意思
- 药罗葛氏是什么意思
- 药老鼠是什么意思
- 药肆是什么意思
- 药胡珠是什么意思
- 药胡知是什么意思
- 药胰皂是什么意思
- 药能是什么意思
- 药能医假病,酒不解真愁。是什么意思
- 药能治假病,酒不解真愁是什么意思
- 药能生人,亦能死人是什么意思
- 药脯是什么意思
- 药腥味儿是什么意思
- 药腥气是什么意思
- 药膏是什么意思
- 药膏疗法是什么意思
- 药膏风是什么意思
- 药膏(软膏)是什么意思
- 药膜法是什么意思
- 药膳是什么意思
- 药膳汤谱是什么意思
- 药膳粥谱是什么意思
- 药膳精谱是什么意思
- 药膳糕谱是什么意思
- 药膳菜谱是什么意思
- 药膳蜜饯谱是什么意思
- 药膳食疗学是什么意思
- 药臼是什么意思
- 药船是什么意思