线性可加模型linear additive model
一个试验观察值按其变异来源划分的线性分解式。若从一个均数为μ方差为σ2的正态总体中随机抽取的观察值xi可分解为总体平均和随机误差两部分,所以其线性可加模型为:
xi=μ+εi (1)
式中 εi为随机误差服从正态分布N(0,σ2)。假如将上述总体分成k个亚总体,各施以不同的处理,设第i处理的效应为τi (i=1,2,…,k),则第i亚总体的平均数为μi=μ+τi。从任一亚总体随机抽出的观察值xij(i=1,2,…,k,j=1,2,…表示观察序数)的线性可加模型为:
xij=μ+τi+εij (2)
这就是单向分组资料中观察值的数学模型。根据试验设计不同可以有不同的线性可加模型,但它们有一共同特点,即各分量都取一次项,故称之为线性可加模型。如双向分组资料中观察值xij的线性可加模型为:
xij=μ+τi+ρj+εij (3)
式中 τi为因素A第i水平的效应,ρj为区组j的效应。在式(2)中,εij服从正态分布N(0,σ2),但根据τi的性质不同,可分为固定模型和随机模型。所谓固定模型是指试验的各处理都抽自特定的处理总体,分别遵循正态分布N(μi,σ2),处理效应τi=μi-μ是固定的常量,并满足 τi=0,试验目的在于研究τi。如重复做试验,所用的处理将是同一套的,即处理效应是固定的。根据式(2)模型可导出方差分析中误差均方S
τi=0,试验目的在于研究τi。如重复做试验,所用的处理将是同一套的,即处理效应是固定的。根据式(2)模型可导出方差分析中误差均方S 2是σ2的估值,处理均方St2是σ+nk2i的估值,其中k2i=
2是σ2的估值,处理均方St2是σ+nk2i的估值,其中k2i=
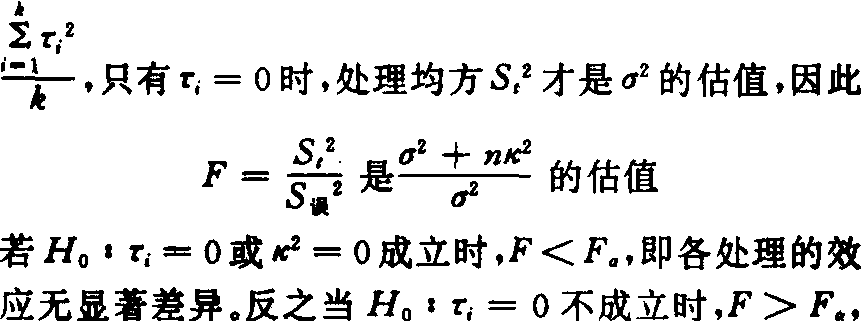
即k2>0。所谓随机模型是指试验中各处理皆抽自正态分布N(0,σ2τ)的一组随机样本,即处理效应τi是随机的遵循正态分布N(0,σ2τ),试验目的不在于研究τi本身的大小,而在于研究τi的变异程度,即σ2τ。所以,方差分析所测验的是H0:σ2τ=0,HA:σ2τ>0,统计推断的不是某些供试处理的效应大小,而是关于抽出这些处理的总体情况,这里误差均方S误2估计是σ2,而处理均方S2
 估计的是σ2+nσ2r,因此
估计的是σ2+nσ2r,因此![]()
在H0:σ2
 =0的假设下,F才能与F
=0的假设下,F才能与F 比较。显然固定模型和随机模型的分析重点不同,前者在于对τi的分析,后者在于对σ2
比较。显然固定模型和随机模型的分析重点不同,前者在于对τi的分析,后者在于对σ2 的分析。农化研究的试验资料大多属于固定模型,如肥料用量试验和肥料品种试验等均为固定模型。连续多年进行的肥料试验中年份效应为随机模型。
的分析。农化研究的试验资料大多属于固定模型,如肥料用量试验和肥料品种试验等均为固定模型。连续多年进行的肥料试验中年份效应为随机模型。- 直落是什么意思
- 直落三是什么意思
- 直蓋是什么意思
- 直虹是什么意思
- 直虹贯垒是什么意思
- 直行是什么意思
- 直行和右转弯是什么意思
- 直行和左转弯是什么意思
- 直行子是什么意思
- 直行播种是什么意思
- 直行铭文双凤镜是什么意思
- 直衕通是什么意思
- 直补是什么意思
- 直表婚是什么意思
- 直袋是什么意思
- 直装子是什么意思
- 直裆是什么意思
- 直裰是什么意思
- 直裰儿是什么意思
- 直裰子是什么意思
- 直裾是什么意思
- 直襟是什么意思
- 直襬是什么意思
- 直西是什么意思
- 直见是什么意思
- 直观是什么意思
- 直观传播报道是什么意思
- 直观动作思维是什么意思
- 直观图是什么意思
- 直观性原则是什么意思
- 直观教具是什么意思
- 直观教具演示法是什么意思
- 直观教学是什么意思
- 直观教学课是什么意思
- 直观教育是什么意思
- 直观教育学会是什么意思
- 直观显示是什么意思
- 直观模拟法是什么意思
- 直观法是什么意思
- 直观演示法是什么意思
- 直观(/电化)教学法是什么意思
- 直观菜谱是什么意思
- 直观行动思维是什么意思
- 直观识字法是什么意思
- 直观询问显示终端是什么意思
- 直视是什么意思
- 直视前旌掣,遥闻后骑鸣。是什么意思
- 直视失溲是什么意思
- 直视式瞄准具是什么意思
- 直视彩色电视接收机是什么意思
- 直视的样子是什么意思
- 直视钳穿法输精管结扎术是什么意思
- 直觉是什么意思
- 直觉——表现说是什么意思
- 直觉与理性是什么意思
- 直觉主义是什么意思
- 直觉主义伦理学是什么意思
- 直觉主义逻辑学派是什么意思
- 直觉型人格是什么意思
- 直觉思维是什么意思