加总问题
加总问题problem of aggregation
由于总量数据是由个量数据加总而成,但加总过程并非简单汇总,而是在个量数据基础上经过加工处理才得到总量数据。无论在哪一个汇总层次上作处理,其结果必定是使所得的宏观数据不再等于微观数据的简单总和。比如t期有n个家庭,每个家庭的消费函数是:
ci=αi+βiyi(i=1,2,3,…n)
其中ci、yi分别表示第i个家庭在t时期的消费支出与收入。αi为当收入为0时的消费支出,βi为边际消费倾向。若将n个家庭的消费函数进行简单的加总,则得: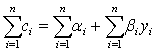
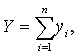 总消费支出
总消费支出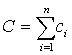 时作的宏观模型为:
时作的宏观模型为:
C=α+βY
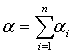 含义清楚,但βY何时与
含义清楚,但βY何时与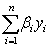 相等?只有两种情况:
相等?只有两种情况:一种是,当β=β1=β2=…=βn时,
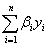
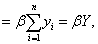 但这非常理想化,因为所有家庭的边际消费倾向不太可能都相同。
但这非常理想化,因为所有家庭的边际消费倾向不太可能都相同。另一种是,β可解释为加权平均,即β*=
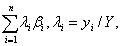 此时:
此时: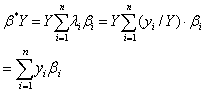
但由于λi将随收入分布而变化,使β*不是常数,这与β意义不符,总之,加总后对真实的微观模型将产生偏离。Theil讨论了使期望偏离最小的加总,谓之最优加总。近年来,从个量过渡到总量所遇到的理论问题也是研究领域活跃的问题。
☚ 个量(微观)数据与总量(宏观)数据 非实验数据 ☛
- 田波扬墓是什么意思
- 田波揚是什么意思
- 田泥是什么意思
- 田泽民是什么意思
- 田洋是什么意思
- 田洎奉使渎职案是什么意思
- 田洪是什么意思
- 田洪都是什么意思
- 田流是什么意思
- 田浚是什么意思
- 田涂坺是什么意思
- 田涛是什么意思
- 田涛(1)是什么意思
- 田涛(2)是什么意思
- 田涛(3)是什么意思
- 田润初是什么意思
- 田润身是什么意思
- 田淑君是什么意思
- 田淑扬是什么意思
- 田清馨《醒着做梦》记叙高中作文是什么意思
- 田游岩是什么意思
- 田游畋游是什么意思
- 田湘藩是什么意思
- 田湜是什么意思
- 田湾核电站是什么意思
- 田湾沟是什么意思
- 田源是什么意思
- 田溪水是什么意思
- 田滋查人诬告县尹案是什么意思
- 田满川据城作乱案是什么意思
- 田漏是什么意思
- 田漢是什么意思
- 田澄是什么意思
- 田激扬是什么意思
- 田炜是什么意思
- 田炯錦是什么意思
- 田炯锦是什么意思
- 田炳煊是什么意思
- 田烈是什么意思
- 田烔锦是什么意思
- 田烛是什么意思
- 田熟是什么意思
- 田燭是什么意思
- 田燮吾是什么意思
- 田爱民是什么意思
- 田父是什么意思
- 田父之功是什么意思
- 田父之获是什么意思
- 田父可坐杀是什么意思
- 田父可坐杀。是什么意思
- 田父坐杀是什么意思
- 田父得玉是什么意思
- 田父怖玉是什么意思
- 田父献曝是什么意思
- 田父玉尺是什么意思
- 田父草际归。是什么意思
- 田父草际归,村童雨中牧。是什么意思
- 田父野叟是什么意思
- 田父野老是什么意思
- 田牛是什么意思